Fearless deployments
Working at a small, young and frugal non-profit, I do not have the luxury of specialised testers giving new features a run-through before they go live. Nevertheless, because our code runs on the websites of other organisations, we have to make absolutely sure that it will not break. At the same time we want to be able to iterate quickly as we adapt to a rapidly changing environment. We manage to balance these two requirements by a variety of measures. Combined, they result in an excellent developer experience, in which I can regularly and confidently deploy code to production.
In this post, I will discuss our approach, starting with the relatively standard elements, building up to the more exciting cutting-edge techniques. All of this uses freely available open source projects.
The basics: a build pipeline
Like many projects, we have set up a build pipeline: a set of tasks that get run every time code gets pushed to the central repository. This pipeline runs a few basic checks before and after code gets merged into master: does the code build successfully, do all unit tests succeed, and what code is covered by them? If a pipeline fails, I receive an email notification. If there's a related open merge request, it will display a warning before merging.
This pipeline already removes a lot of potential for human error. For example, if I forget to run unit tests locally and I break some, that code will not make it into the main codebase without me noticing. Likewise, I could forget to check in parts of my code. Even though tests would still succeed for me locally, the pipeline would fail, and I will immediately be notified. This is vastly preferable over distributing incomplete and broken code to other developers or, worse, users.
Artifacts like e.g. the code coverage report produced during the pipelines are also visible to all team members.
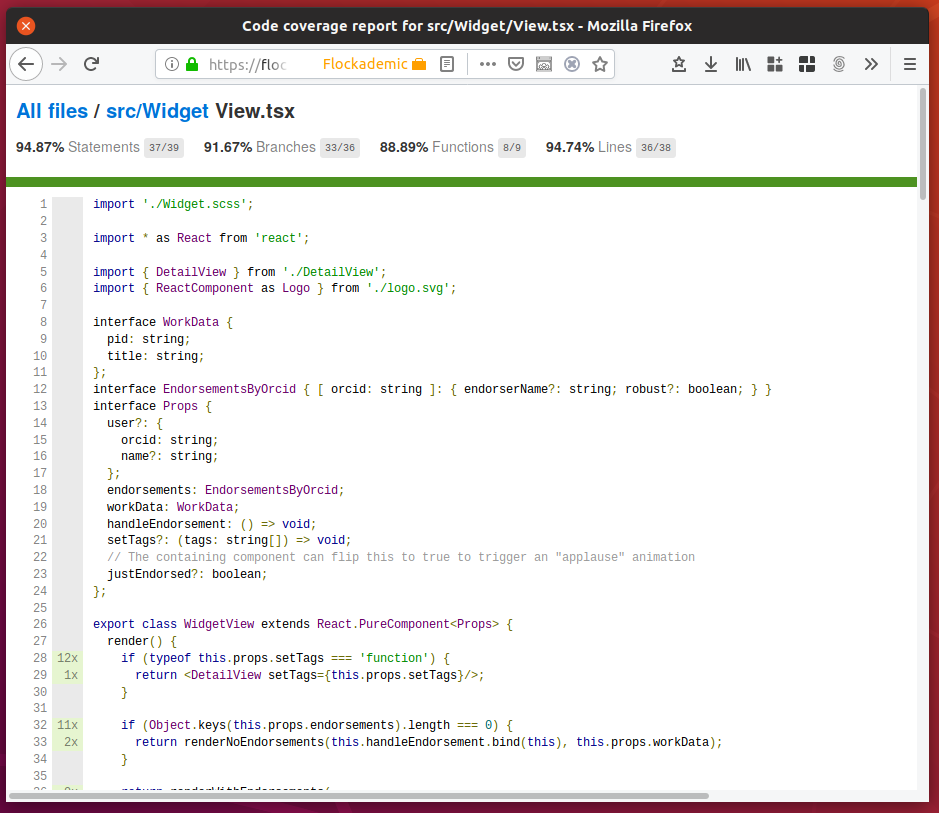
Our pipelines are powered by GitLab CI/CD.
Review apps
Review Apps are the backbone of everything that is to come. The basic concept of a review app is spinning up an entirely new and disposable production-like environment for every branch, with that branch's code deployed to it. My basic workflow is to create a new branch whenever I start solving an Issue, straight from the GitLab interface.
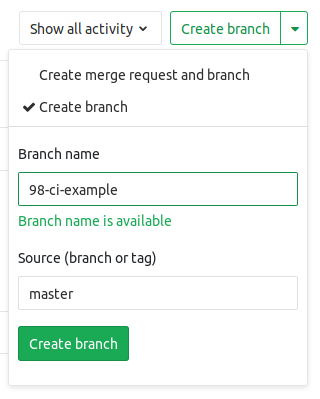
These branches are automatically named using the format <issue number>-<issue description>, e.g. 98-ci-example. Upon creating that branch, a new pipeline automatically runs, deploying the code in that branch to https://98-ci-example-review.plaudit.pub.

The advantages of review apps are numerous. It allows me to easily verify whether and how my code works in a clean environment. It tells me that deployments still work as expected, and hence will likely do so when I deploy my code to production as well. And finally, it enables a variety of automated sanity checks on the live application, such as checking for performance regressions or potential security issues.
The primary tool used to provision these new environments is TerraForm. It allows you to define the infrastructure you need using a configuration file, and to pass the relevant branch name as a parameter.
End-to-end tests
Of course, I could visit the deployed review app to check whether everything's OK... But why go through the effort when that, too, can be automated? After a review app gets deployed, the build pipeline automatically fires up Chrome and Firefox. They will then visit the newly deployed app, try to run through a few basic scenario's, and then report on whether they were able to do so successfully.
These end-to-end tests buy me two things. First, they can warn me when a deployment was unsuccessful. Even a simple test that literally just visits the page and checks whether a single DOM element is present is enough to tell you whether the new infrastructure was successfully set up, the code was deployed successfully, and the server is running as expected. Second, they run some basic tests trying to navigate the app by keyboard - an important accessibility concern that is easy to mess up.
The end-to-end tests use Selenium for browser automation, and WebdriverIO to run the checks.
Storybook
Our primary product is a widget that can be in many different states, and adapts its looks to the space it's allotted. It is therefore useful to be able to see what the widget looks like in all those different variations, without having to reproduce all the steps required to get the widget into those states. To facilitate this, with every review app we also deploy a storybook.
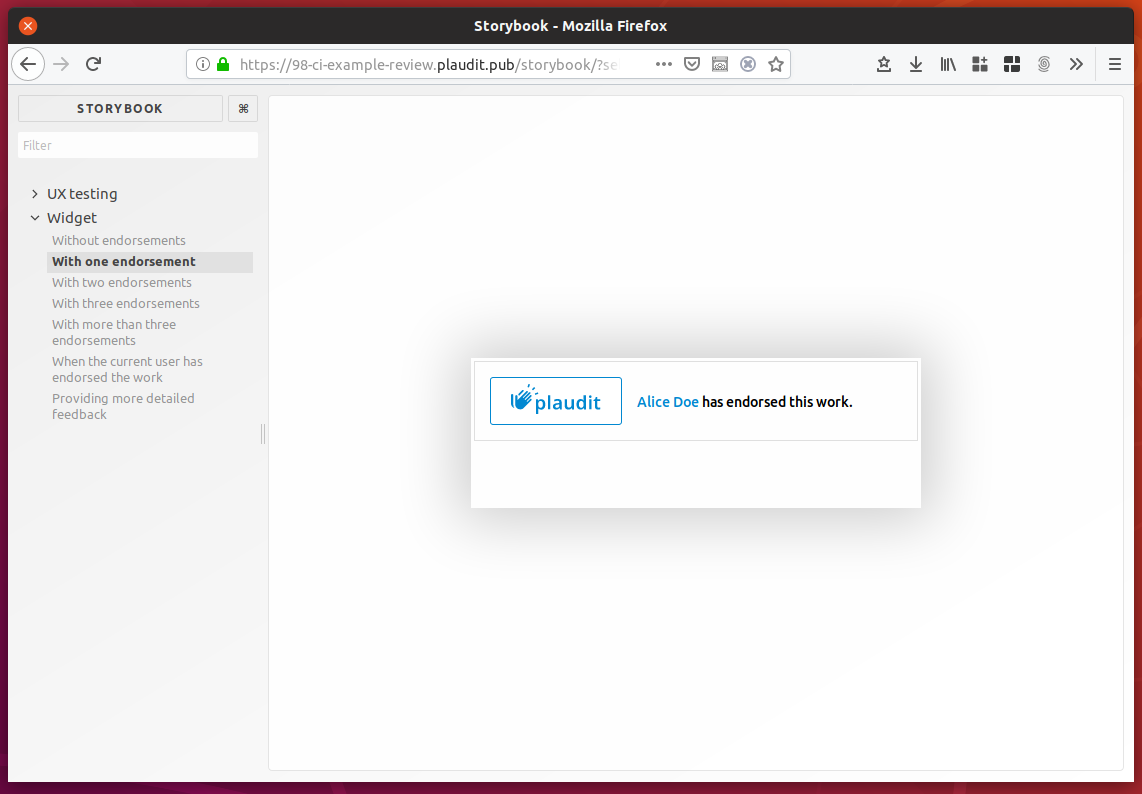
Using the storybook, it's just a single click in order to inspect the various states the app can be in: no data, some data, too much data, logged in, logged out, etc. This makes it very easy to quickly check the impact of CSS changes on the widget in all its different faces.
The storybook is made possible by the aptly-named project Storybook.
Visual regression tests
Still, having to manually inspect the widget in all its various states on every change is rather time-consuming. Luckily this, too, can be automated. Whenever a pipeline is run, the storybook is opened in a browser, and screenshots of the widget in every state are compared to checked-in reference screenshots. When the two diverge, the pipeline fails and a report is generated highlighting the differences between the deployed widget and the reference image.
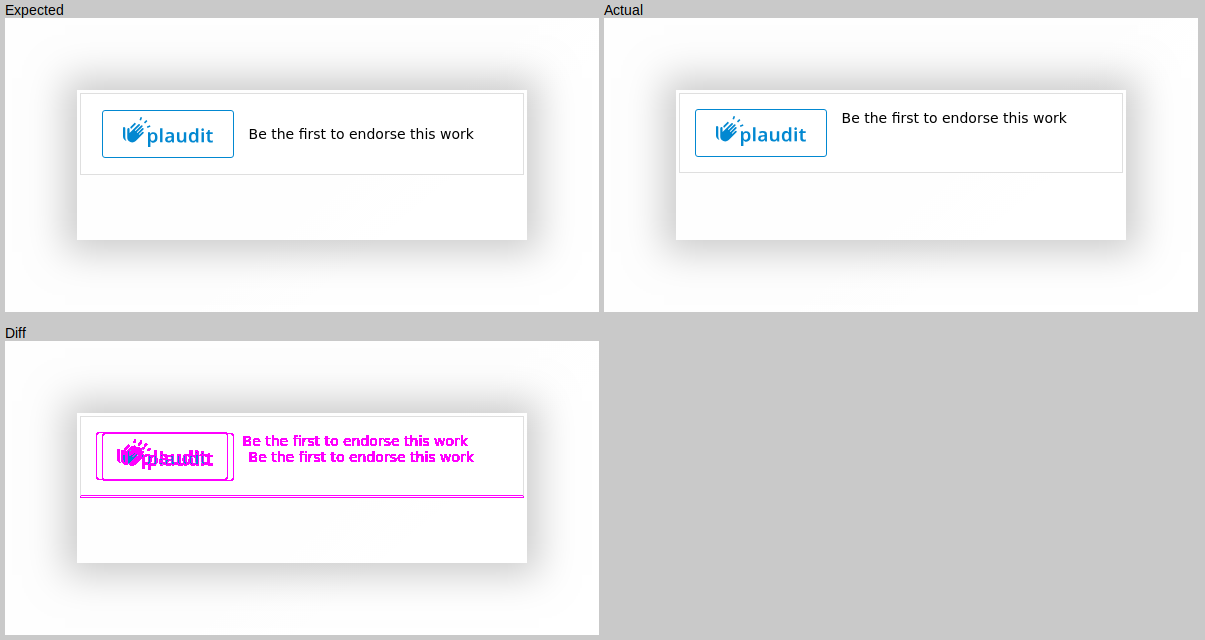
This will make sure that I receive a notification whenever I alter the layout of the widget, which is very helpful when those changes were unintentional. For example, I recently found out that Chrome does not support <button> elements acting as flex containers, due to which a supposedly minor accessibility change ended up messing up the layout in a specific state.
The regression tests are executed by Gemini.
Wrapping up
Combined, all these tools provide me with a lot of reassurance whenever I am ready to push my code to production. They have prevented repeated occurrences of actual problems I have run to in the past, and seeing a row of green checkmarks before merging into master provides a lot of reassurance.
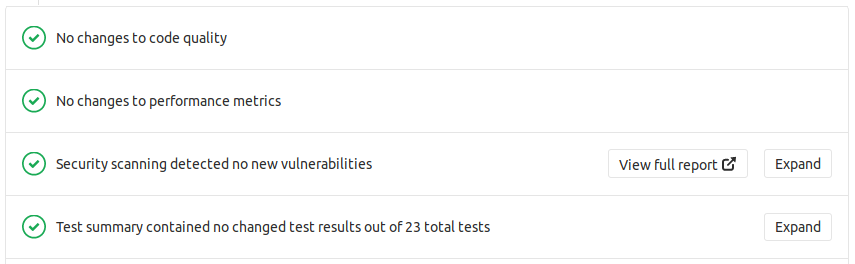
These tools were added incrementally over time, in response to actual encountered problems. I hope that showing what's possible using off-the-shelf open source tools will encourage you to investigate what could be possible and useful in your own projects as well. The exact setup will vary per project, but you're welcome to look at ours as a starting point!

This work by Vincent Tunru is licensed under a Creative Commons Attribution 4.0 International License.